LRU是Least Recently Used的缩写,即最近最少使用,是一种常用的页面置换算法,选择最近最久未使用的页面予以淘汰。笔者今天挑选了OC端的YYMemoryCache和服务端的Redis这两个LRU算法的应用场景和大家一起分享下。
一、YYCache中的LRU
YYMemoryCache是OC的一个缓存库YYCache的内存缓存部分,使用双向链表+字典实现的LRU淘汰算法。
我们先来看看节点的数据结构设计

YYLinkedMapNode是它的存储节点,设计了prev和next两个指针记录双向链表的前后数据。key和value是数据键值对,同时针对内存容量及访问时间两种淘汰策略设计了cost和_time。
再看下容器的数据结构
YYLinkedMap是一个链表+字典的结构,存储数据部分dic是使用Core Foundation框架下的CFMutableDictionaryRef字典,C语言实现的,相较于Foundation框架下的NSDictionary,没有ARC的内存管理,更加精简。
关于Core Foundation和Foundation的关系就牵扯到乔布斯当年收购NeXTSTEP的故事了,有兴趣的同学可以查阅相关资料。
OC提供了一套Toll-Free Briding可以自动转换部分Core Foundation框架和Foundation框架相配对的数据类型。
totalCost和totalCount是用于根据内存大小和存储数量纬度进行的统计,方便进行淘汰。head和tail是链表的头部和尾部记录位置。releaseOnMainThread是数据删除的时候,指定释放的线程在主线程,releaseAsynchronously是异步释放数据的控制。
我们看下插入和访问数据时LRU算法是怎么操作的: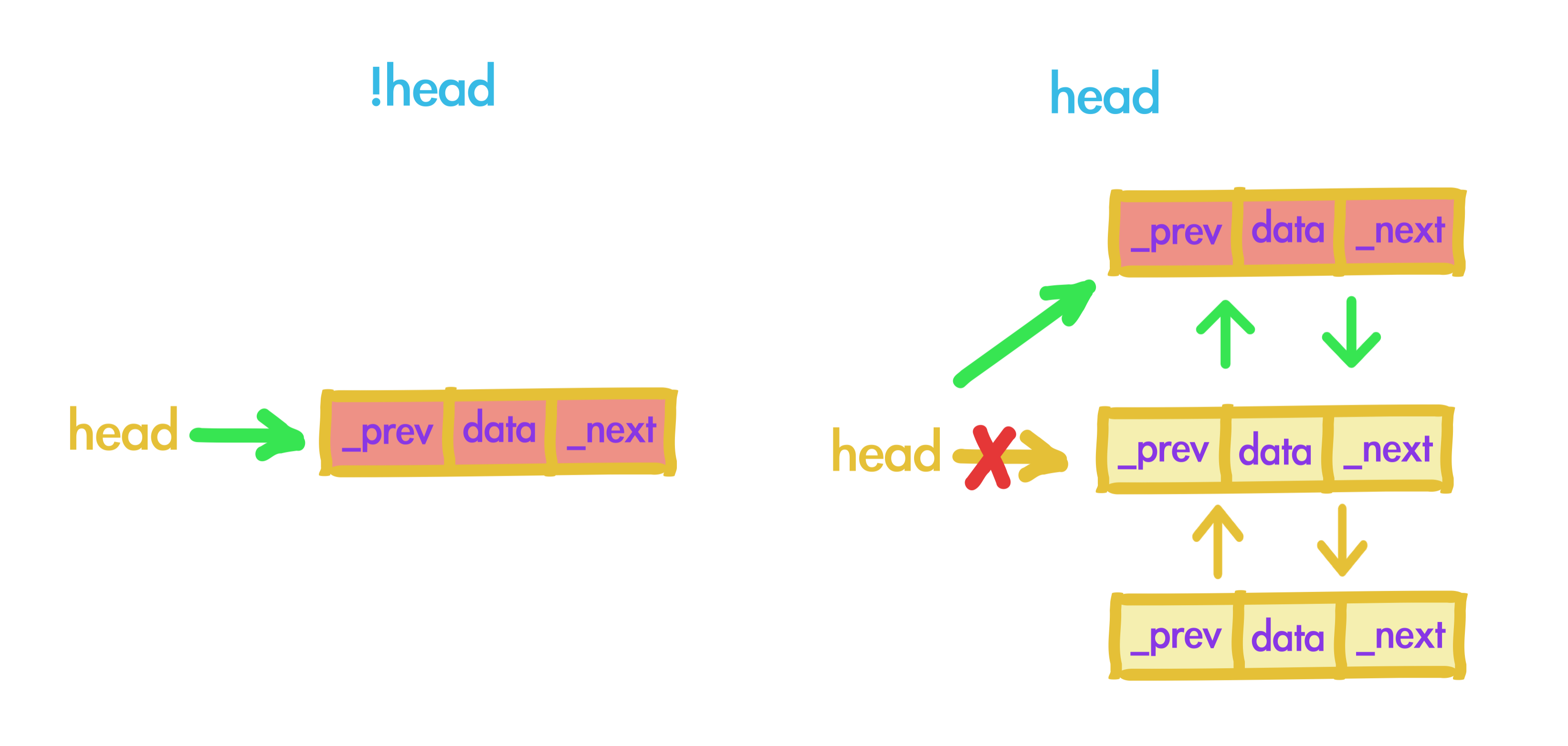
插入一个新节点,对应_YYLinkedMap中的insertNodeAtHead方法,处理两种情况:
1、链表头部不存在,直接插入。
2、链表头部存在,处理原head数据的prev指针指向和插入数据的next指针指向,head指针指向插入数据。
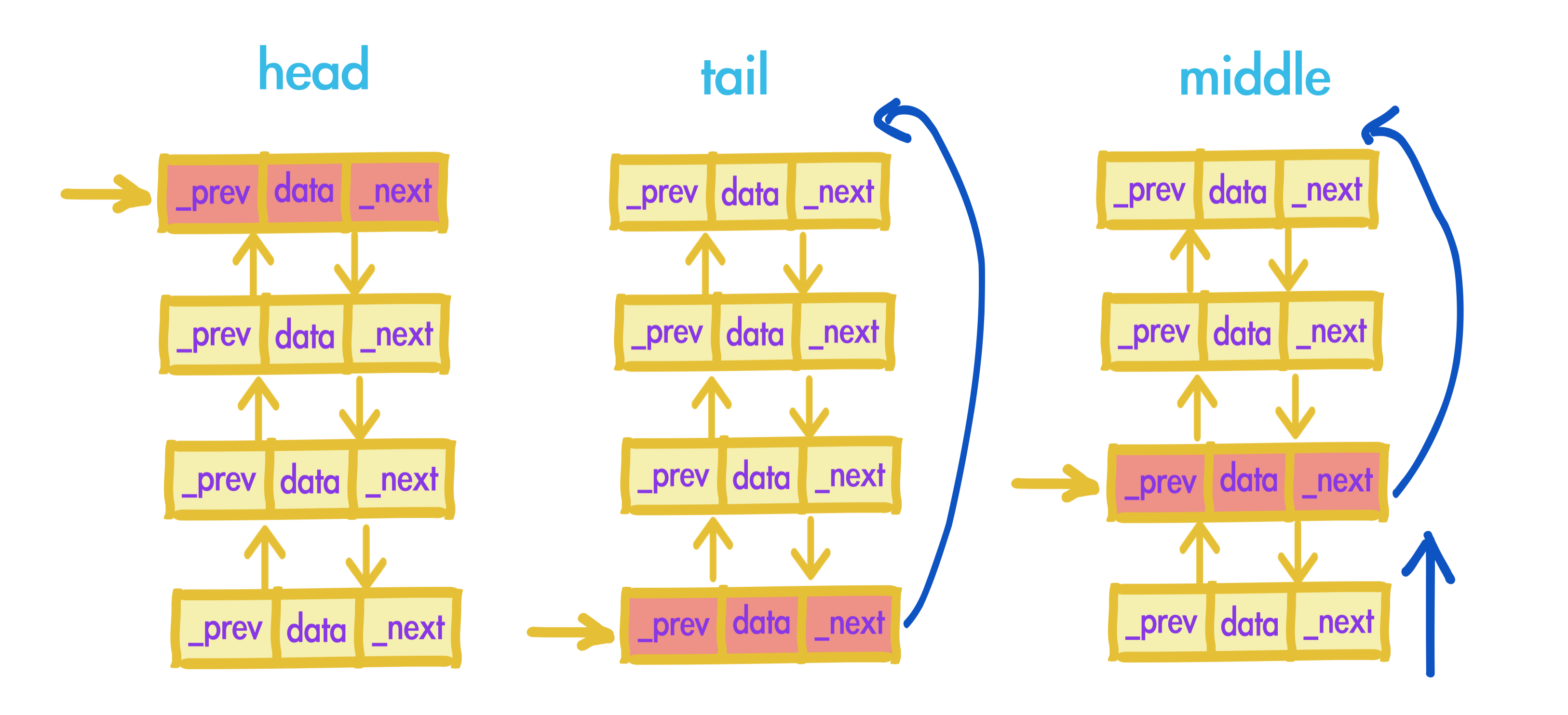
访问已存在节点,对应_YYLinkedMap中的bringNodeToHead方法,分为三种情况:
1、访问节点是链表头部,无操作。
2、访问节点是链表尾部,尾部pop操作,并将该节点变更为_head指针。
3、访问节点是中间部分,对该节点进行删除,并将该节点变更为_head指针。
YYMemoryCache设计有内存消耗cost、数据总数count、存储时间age三个维度的数据淘汰限制。
淘汰逻辑是: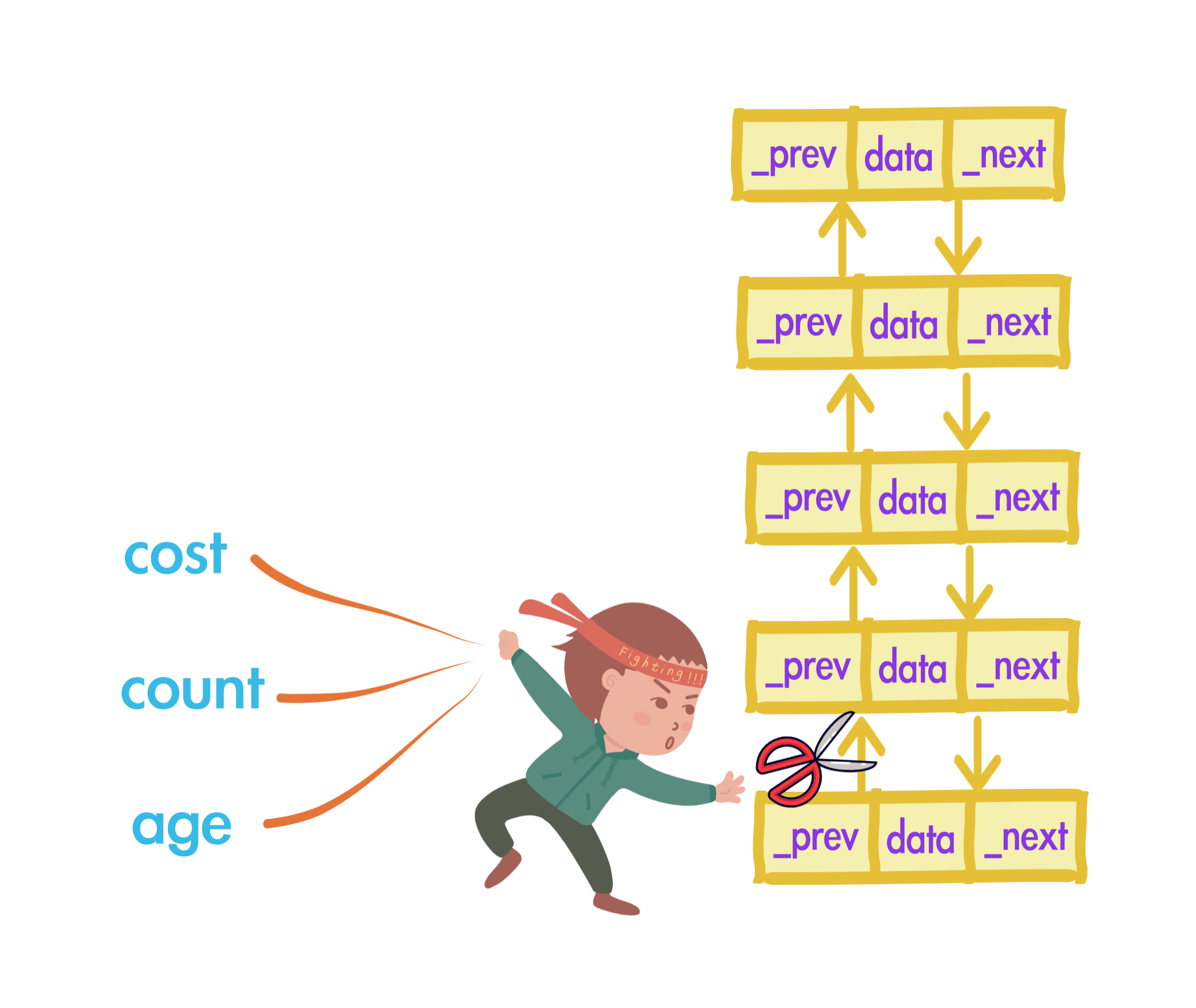
1、总的内存消耗totalCost超出了阈值costLimit的时候,从尾部开始往上遍历淘汰数据。
2、总的数据总数totalCount超出了阈值countLimit的时候,从尾部开始往上遍历淘汰数据。
2、总的数据总数totalAge超出了阈值countLimit的时候,从尾部开始往上遍历淘汰数据。
整个操作是在pthread_mutex_t,linux的互斥锁里进行的,保证数据安全。并且由于releaseAsynchronously和releaseOnMainThread两个参数的设计,将数据淘汰后制定到指定线程中销毁,这段设计还是相当精彩的。
同时,YYMemoryCache设置了收到系统内存警告以及app压后台操作进行内存缓存释放的操作,默认值都是YES。保证了应用的高可用性。
二、Redis中的LRU
Redis并没有使用双向链表实现一个lru算法。
首先看一下Redis数据节点的数据结构redisObject,每个redisObject都有一个24bit长度的lru字段,保存访问时间戳。这个时间戳是redis时钟计算的,由getLRUClock函数进行计算得出。
redisObject只有2种情况会更新lru,创建时(createObject)和访问时(lookupKey)。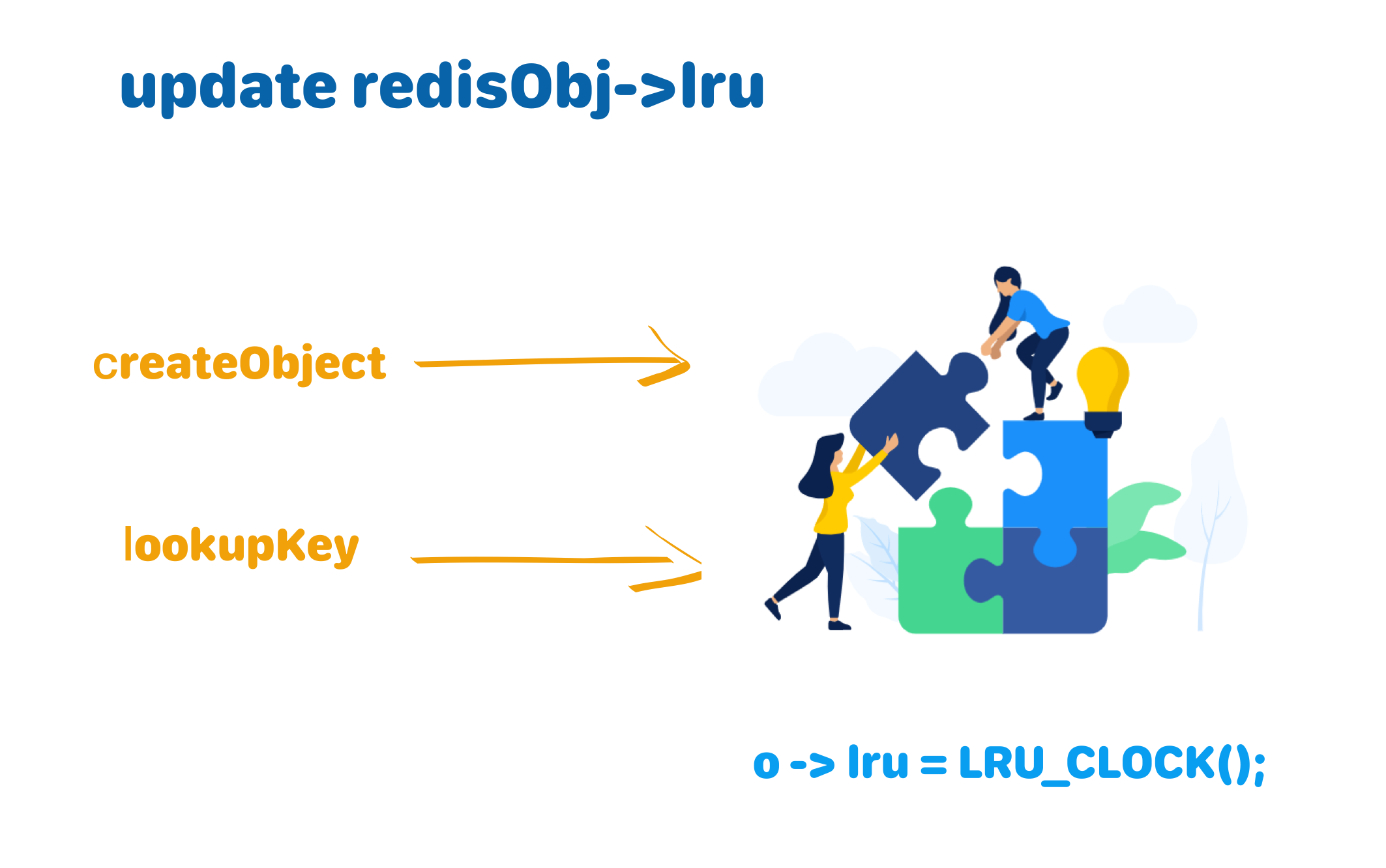
实际运算时,是根据当前时间戳计算的空闲时间idle time,以下简称idle。函数实现参见estimateObjectIdleTime。
现在看看Redis怎么运用LRU算法进行数据淘汰的,
在Redis2.8之前,算法很简单,随机从dict中取出5个key,淘汰一个idle最大的。
Redis3.0之后进行了改版: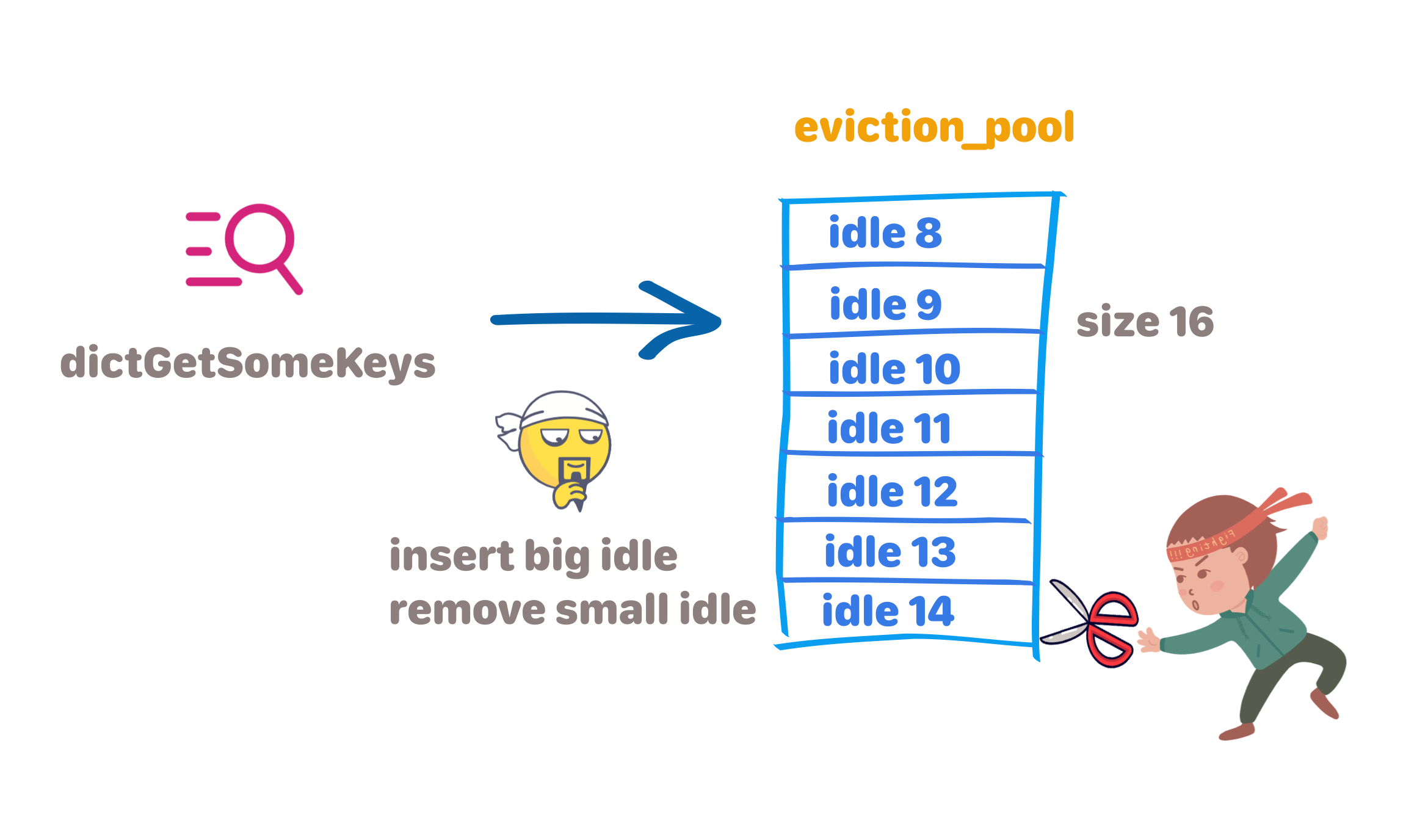
1、设计了回收池eviction_pool。eviction_pool为数组,大小为16个元素,eviction_pool中key按idle从小到大排序。
2、dictGetSomeKeys随机选取N个key,如果它的idle比eviction_pool里面的Key的idle还要大,就把它添加到eviction_pool里面去,直到eviction_pool放满。
3、放满后,每次有新key放入,需要将eviction_pool中idle最小的key移出。
4、需要淘汰时,直接从eviction_pool中选取idle最大的key,再通过key读取数据进行淘汰。
看下官方文档的淘汰效果(图片来自Redis官方文档)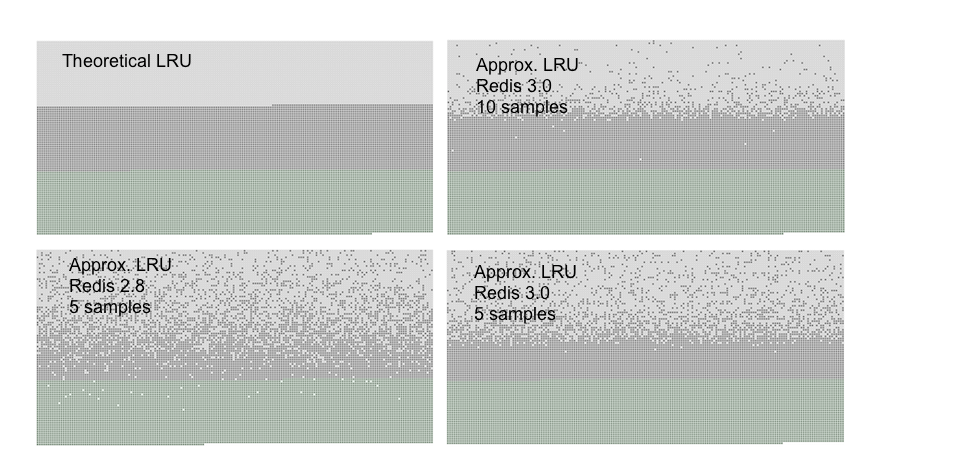
Theoretical LRU为理想中的lru算法,新增加的key和最近被访问的key都没被淘汰。
Redis 2.8中随机采样5个key时,新增加的key和最近被访问的key都有一定概率被淘汰。
Redis 3.0中随机采样5个key时,效果稍好一些。增加为10个key效果更佳。
三、对比
1、YYMemoryCache使用双向链表实现的LRU,能实现数据的精确淘汰。
其数据结构搭配了字典和双向链表搭配的方式,使得访问数据时查找时间复杂度由O(n)降低到O(1)。
但,每个节点需要维护prev和next指针,这部分内存消耗无法避免。
2、Redis的LRU,特别是3.0以后,回收池的设计,将全局的排序问题,转化成了局部排序。
遍历16个元素的eviction_pool数组效率大大提升,而在若干次随机采样之后,eviction_pool里的元素就代表着全局key,而每次采样更新后,能够保证eviction_pool里的key是随机选择过的idle time最大的。
需要淘汰时,就从数组尾部淘汰即可。
这种近似的思想,提升了效率,很值得借鉴。